Lora

为什么LoRA可以work?
- 大型预训练模型的低秩特性: 在适配下游任务时, 由于大模型存在一个潜在的低维"内在维度"(instrisic dimension), 所以即使把它们随机映射到一个较小的子空间, 他们依然可以高效准确地学习新数据的特性. LoRA就是借鉴的这中低秩思想, 即在适配下游任务时, 可以给预训练的大模型注入一个低秩的可训练的参数矩阵就可以用较少的参数捕捉到特定数据集的主要特性.
- 保持预训练权重不变, 大模型微调往往会导致原有模型出现"catastrophic forgetting"问题,但是LoRA在适配下游任务时冻结了原有参数, 确保预训练模型在适配过程中依然保持预训练阶段学到的能力.
- 灵活性和易分享性: 多个LoRA可以组合使用
- 无推理延迟: LoRA不会在模型推理阶段引入额外的时间开销, 这与adapter这种微调方式有着很大的优势
矩阵初始
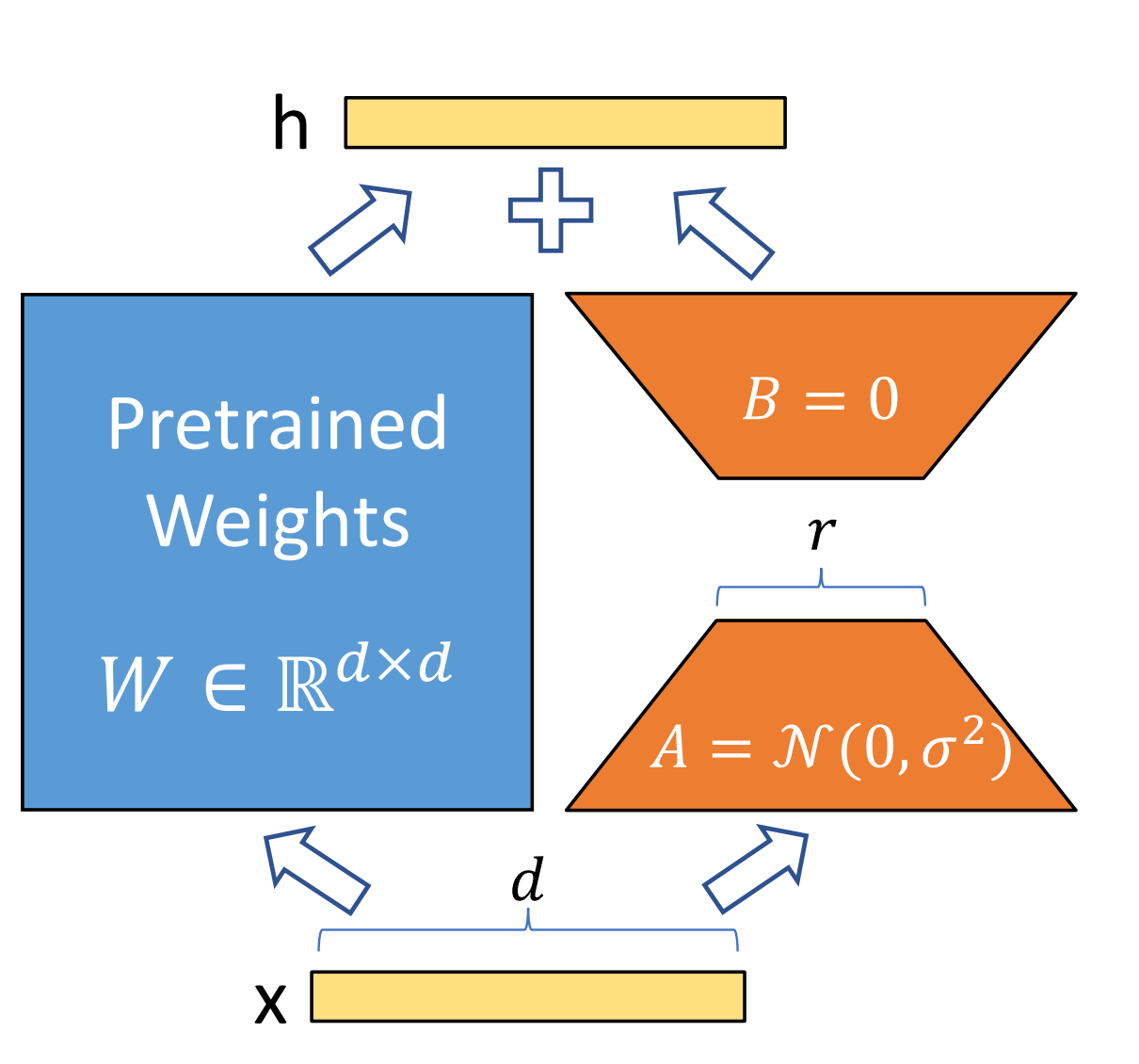 A: 使用随机高斯初始化(Random Gaussian Initialization): lora_down
A: 使用随机高斯初始化(Random Gaussian Initialization): lora_down
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
B: Zero 初始化: lora_up
nn.init.zeros_(self.lora_B)
公式
通常会在LoRA部分�添加一个缩放系数 scale, 即
当scale 系数α为0则完全不使用LORA, 只是用预训练的模型参数.
微软的代码中使用会有一个额外的lora_alpha来计算缩放系数, 即
LoRA选择那个矩阵进行低秩分解
- 理论上任何一个矩阵都可以被低秩分解. 在Transformer架构中, 作者通过实验发现, 只对attention部分进行lora低秩注入就能在下游任务中获得比较好的效果.
- 单独对Wq或者Wk进行分解得到了一个非常低的值,但是通过对Wq和Wv则活得了最好的表现
代码
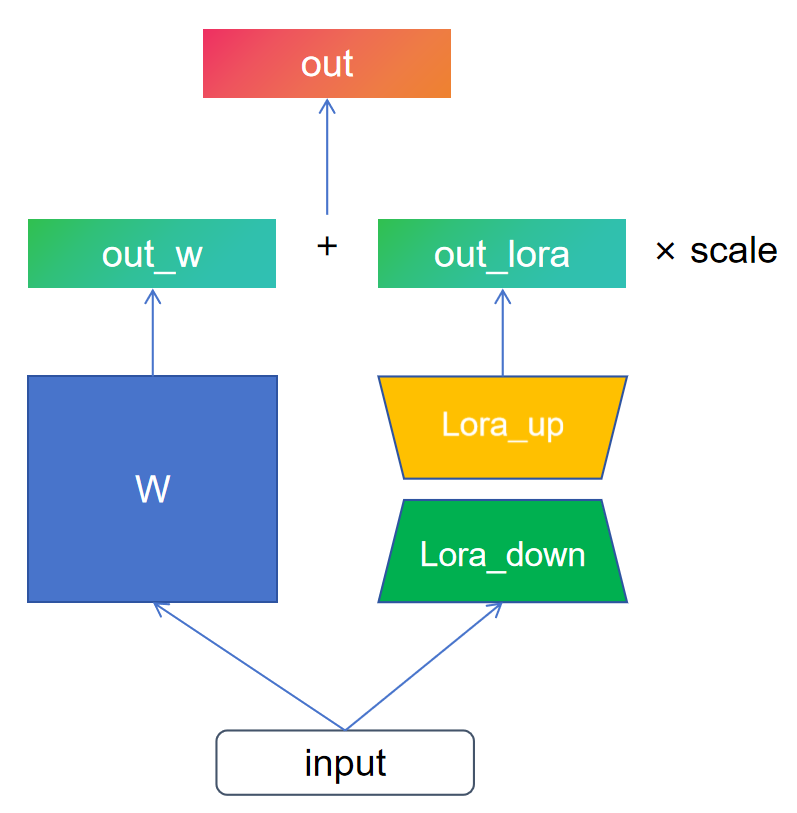
注入线性层
class LoraInjectedLinear(nn.Module):
def __init__(
self, in_features, out_features, bias=False, r=4, dropout_p=0.1, scale=1.0
):
super().__init__()
if r > min(in_features, out_features):
raise ValueError(
f"LoRA rank {r} must be less or equal than {min(in_features, out_features)}"
)
self.r = r
# w
self.linear = nn.Linear(in_features, out_features, bias)
# lora_down
self.lora_down = nn.Linear(in_features, r, bias=False)
# lora_up
self.lora_up = nn.Linear(r, out_features, bias=False)
self.dropout = nn.Dropout(dropout_p)
self.scale = scale
self.selector = nn.Identity()
nn.init.normal_(self.lora_down.weight, std=1 / r)
nn.init.zeros_(self.lora_up.weight)
def forward(self, input):
return (
self.linear(input)
+ self.dropout(self.lora_up(self.selector(self.lora_down(input))))
* self.scale
)
注入Conv2d层
class LoraInjectedConv2d(nn.Module):
def __init__(
self, in_channels: int, out_channels: int, kernel_size,
stride=1, padding=0, dilation=1, groups: int = 1, bias: bool = True,
r: int = 4, dropout_p: float = 0.1, scale: float = 1.0,
):
super().__init__()
if r > min(in_channels, out_channels):
raise ValueError(
f"LoRA rank {r} must be less or equal than {min(in_channels, out_channels)}"
)
self.r = r
# W
self.conv = nn.Conv2d(
in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias,
)
# lora_down
self.lora_down = nn.Conv2d(
in_channels=in_channels, out_channels=r, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups, bias=False,
)
# lora_up
self.lora_up = nn.Conv2d(
in_channels=r, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, bias=False,
)
self.dropout = nn.Dropout(dropout_p)
self.selector = nn.Identity()
self.scale = scale
nn.init.normal_(self.lora_down.weight, std=1 / r)
nn.init.zeros_(self.lora_up.weight)
def forward(self, input):
return (
self.conv(input)
+ self.dropout(self.lora_up(self.selector(self.lora_down(input))))
* self.scale
)